
PyTorch Poetry Generation [Pre-WordHack : Epoch 16 Video]
Another day of testing before going to NYC to perform neural-net poems at WordHack [NYC (Thursday 2/16/2017 @ Babycastles . 7-10pm) w. Sarah Rothberg, John Cayley and Theadora Walsh]
HOPE In the cold weather going out of the snow, She down the lawn. The air moves and grows, while she walks smooth, When a swan is born, And it's almost happening Who knows what to say The change has brought Throwing the first blood in its face.
It’s clear:
Never will this mode of randomized pattern-reasoning replicate the nuanced human heart. More robust ensemble methods that simulate embodied experience, temporal reflexes, and nested community idioms will be required.
Deep learning is still shallow. The cloud does not understand honey, home or heart. Yet in the short-term, this is the future of writing: a computational assistant for an engaged imagination intent on exploring the topological feature-space of potential phrases.
Done:
Modulated the parameters: raised both embedding size and hidden layers to 512. And did a bit more data mining and parsing to increase the corpus size by 1/3 to 20mb of .txt.
Mode: LSTM Embedding size: 512 Hidden Layers: 512 Batch size: 20
Expanded Corpus to over 600,000 lines
639,813 lines of poetry from 5 websites.
Poetry Foundation Jacket2 Capa - Contemporary American Poetry Archive Evergreen Review Shampoo Poetry
Continue reading “PyTorch Poetry Generation [Pre-WordHack : Epoch 16 Video]”
40 Minutes of PyTorch Poetry Generation [Real-time SILENT]
Promising results that reflect the limits of a machine without empathy, skilled as a mimic of pattern, lacking longterm memory, emulating cadence and inflections, yet indifferent to context, experience and continuity.
Code: github.com/jhave/pytorch-poetry-generation
60 minutes of poetry output below the break :
A LAND IN SEASON so much a child is up, so much what he cannot feel has found no knowledg more of age, or of much friends which, nothing thinks himself. spok'n not knowing what is being doing? or else wanting as that
Continue reading “40 Minutes of PyTorch Poetry Generation [Real-time SILENT]”
PyTorch LSTM Day 2 : Killed (after only 40 epochs)
My dream of an immaculate mesmerizing machine to replace all human imagination and absorb it into an engaging perpetual torrent of linguistic cleverness dissipated.
Yesterday, I let the GPU run overnight, expecting to return to 120 epochs and a stunning result.
Instead, on waking the computer in the morning:
----------------------------------------- | end of epoch 40 | time: 452.85s | valid loss 5.84 | valid ppl 344.72 ---------------------------------------- SAVING: models/2017-02-06T17-39-04/model-LSTM-epoch_40-loss_5.84-ppl_344.72.pt Killed
The simulacrum had miscarried. The entire thread had been killed (automatically? by what clause?). Considering the results in glum melancholy, I realized it had been killed because 5 epochs had passed without improvement.
Yet, after dusting off the 40 models that existed, many intriguing gems emerged, spliced they suggest a latent lucidity:
without regret, played with a smooth raid of soiled petals, the color of rage and blood away-- pinched your nose
the unwavering wind brushed the crystal edge from the stack, it came in the mirror adam's-- eleven miles from the unholy relic
and i set off into the absence of old themes, ... looking for the wreck of the rare summers
dark silks and soft blonde feather on pink sky that hid a blue sun where it became dwelling pointing dead its lip rattled its green pride, thread-bare
Code on Github: https://github.com/jhave/pytorch-poetry-generation
Read the entire UNEDITED batch of 40 generated poems of 111 words after the break:
Continue reading “PyTorch LSTM Day 2 : Killed (after only 40 epochs)”
Testing PyTorch on Poems (Preliminary Results)
PyTorch is an early release beta software (developed by a consortium led by Facebook and NIVIDIA), a “deep learning software that puts Python first.”
So since I luckily received an NVIDIA GTX TitanX (Maxwell) before leaving Hong Kong under the generous NVIDIA academic GPU Grant program, and having last week finally bought a custom-build to house it, and 2 days ago finally got Ubuntu installed with CUDA and CUDNN drivers, and having found that the Tensorflow 0.11 version no longer runs under Python 3.6 Anaconda, I decided to give a PyTorch example a try, specifically Word-level language modeling RNN
This example trains a multi-layer RNN (Elman, GRU, or LSTM) on a language modeling task…The trained model can then be used by the generate script to generate new text.
And after only an hour of training on an 11k poem corpus, using the default settings, the results announced “End of training | test loss 5.99 | test ppl 398.41” — Which means that the loss is bad and perplexity is now at the seemingly terrible level of 398….
Then I ran the generate script and the 1000 word text below got generated in less than 30 seconds. I find it stunning. If this is what PyTorch is capable of with a tiny corpus, default settings and a minimal run, language generation is entering a renaissance. Ok, so it’s veering toward the incomprehensible and has little lived evocative phenomenological resonance, but its grasp on idiomatic cadence is creepily accurate. It’s as if it absorbed several semesters of graduate seminars on romantic and post-modern verse:
the embankment
and your face sad like a nest, grew sorry
when your cold work made of snow
broken
and left a thousand magnifies.a little cold, you plant but hold it
and seems
the slight arts? face, and ends
with such prayer as the fingers do,
this reorganizing contest is how
to be murdered
throwing it
into the arteries obscurity goes disc whispering whole
affairs, now your instinct
does a case,
defense. on her eye, you do not know that every homelands
is didn’t at the
risk very psychiatrists, just under bay.by the living of life’s melancholy grate.
i have found a
wild orange in eden, eight hazy years guzzles
her neck at the grave turn into every mythological orbit of
distances,
person’s there–see then are we told what we understand
won’t take the slightest danger
or the
size of what it means to take up if you can,
tongue. only your eye exultant whitens again will
happen.
i think that the four-oared clouded of one stick in flowerpot
is part of an antique little
register on a hiatus
till i try for you.
i wash up the door my knee will be
high.
if i refuse a limits as i can lift my hand rubicon.i can see her
above the stove tide
hip. orange as a breaking sty.
Continue reading “Testing PyTorch on Poems (Preliminary Results)”
THE ONLY PERSON WHO LIKED THIS WAS A BOT
Wavenet-for-Poetry-Generation [REHEARSAL]
An improvised reading,
of generated poetry made as it is born,
at 201701110-1347.
3 Survivors : 1397 Models, 16,548 txt files, 8+ hrs of video (& no poems yet): Wavenet for Poem Generation: Secondary Results (After training for 6+ weeks continuously)
From 26-10-2016 to 11-12-2016, Wavenet-for-Poem-Generation (code on github) trained on an 11k poem corpus simultaneously in 7 different tabs of a terminal window (on a 8-core G5 each tab occupied a core of the CPU) — each tab was using different parameter settings.
In the end only 3 settings exceeded 100k training epochs before succumbing to the exploding gradient dilemma (detailed here).
The 3 surviving threads were known as 26-03, 38-59, and 39-18 — each folder name references its time of birth, the time it began receiving models from its thread, the neural network learning as it groped its way thru the corpus. These threads alone (of many myriad attempts) lived longest and saved out hundred of models with loss under 0.7.
SILENT VIDEOS of REALTIME POEM GENERATION
Warning: these videos are long! Total viewing time: 8+ hours.
Each is a silent realtime screen-capture of neural net models generating poems.
Poems from the same model are generated side-by-side to allow for comparative viewing. Note how young models create poems that rampage logic, merge less. Mature models from 50k-110k begin to emulate deflections and balance, concealing and revealing. And ancient models (after they suffer an exploding gradient data hemorrhage) create poems full of fragments and silences, aphasia and lack, demented seeking.
Suggested viewing: put on an extra monitor and let run. Consult occasionally as if the computer were a clever oracle with a debilitating lack of narrative cohesion.
SAMPLE OUTPUT
16,548 text file poems on github
PARAMETER SETTINGS
Common to each survivor were the following parameters:
- Dilations = 1024
- SkipChannels = 4096
- Quantization Channels = 1024
Dilation channels were different for each survivor : 8, 16, 32.
Training process: complete terminal output of training runs .
FOLDER DETAILS
A subset of the models used in demo readings can be found online at github.
39-18 (2016-10-26T18-39-18)
Dilation Channels : 8
Born: 26 October 2016 at 03:29
Died: Sunday, 11 December 2016 at 11:28
Models: 458
Epochs: 145070
Size: 80.37GB
38-59 (2016-10-27T10-38-59)
Dilation Channels : 16
Born: 26 October 2016 at 03:29
Died: Sunday, 11 December 2016 at 8:03
Models: 475
Epochs: 150000
Size: 130.68GB
26-03 (2016-10-26T15-26-03)
Dilation Channels : 32
Born: 26 October 2016 at 03:29
Died: Sunday, 11 December 2016 at 11:28
Models: 464
Epochs: 145070
Size: 98.1GB
Wavenet for Poem Generation: preliminary results
For the past week, I’ve been running a port of the Wavenet algorithm to generate poems. A reasonable training result emerges in about 24 hours, — a trained model that can generate immense amounts of text relatively quickly. On a laptop. (Code: github). By reasonable I mean the poems do not have any real sense, no sentient self, no coherent narrative, nor epic structure. But they do have cadence, they do not repeat, new words are plausible, and they have adopted a scattered open line style characteristic of the late twentieth century corpus on which they were trained. Much more lucid than Schwitters’ Ursonate, output is reminiscent of Beckett’s Not I : ranting incandescent perpetual voice.
Results
Remember, these are evolutionary amoebas, toddlers just learning to babble. The amazing thing is that without being given any syntax rules, they are speaking, generating a kind of prototypical glossolalia poem, character by character. Note: models are like wines, idiosyncratic reservoirs, the output of each has a distinct taste, — some have mastered open lines, others mutter densely, many mangle words to make neologisms — each has obsessions. The Wavenet algorithm is analogous to a winery: its processes ensure that all of the models are similar. Tensorflow is the local region; recursive neural nets form the ecosystem. The corpus is the grapes.
Intriguing vintages-models :
Dense intricate Model 33380 — trained with 1024 skip channels and dilation to 1024 (read a txt sample)
the mouth’s fruittiny from carryinga generative cup
Loose uncalibrated Model 13483 with loss = 0.456, (1.436 sec/step) trained on 2016-10-15T20-46-39 with 2048 skip channels and dilation to 256 (read a txt sample)
at night, say, that direction.
sleepsnow. so you hear we are shakingfrom the woods
Full results (raw output, unedited txt files from the week of Oct 10-16th 2016) here.
it’s there we brail,beautiful fullleft to wish our autumn was floor
Edited micro poems
…extracted from the debris are here.
through lust,and uptight winking coldblood tree hairsburnedin loss
Code
Python source code + a few trained models, corpus and some sample txt: on github which will be updated with new samples and code as it emerges.
Details
The Model number refers to how many steps it trained for. Skip channels weave material from different contexts. On this corpus, larger skip channels produce more coherent output. Dilations refer to the size of the tensors of the encoder-decoder: eg. [ 1, 2, 4, 8, 16, 32, 64, 128, 256, etc… ] Higher values up to 1024 seem to be of benefit, but take longer to train. Loss is the mathematical calculation of the distance between the goal and the model; it is a measure of how tightly the model fits the topological shape of the corpus; as models are trained, they are supposed to learn to minimize loss; low loss is supposed to be good. For artistic purposes this is questionable (I describe why in see next section). For best results, in general, on this corpus: 10k to 50k steps, 1024 dilations, a skip channel of 512 or more, and (most crucial) loss less than 0.6.
Learned
Loss is not everything. An early iteration model with low loss will generate cruft with immense spelling errors. Thousands of runs later, a model with the same loss value will usually produce more sophisticated variations, less errors. So there is more going on inside the system than is captured by the simple metric of loss optimization. Moreover if the system is about to undergo a catastrophic blowout of loss values, during which the loss ceases to descend toward the gradient and exponentially oscillates (this occasionally occurs after approx 60k steps). Generated text from poems just before that (with good loss values below 1.0 or even excellent loss values below 0.6) will produce some ok stuff interspersed with long periods of nonsense or —— repeated **** symbols. These repetitive stretches are symptoms of the imminent collapse. So loss is not everything. Nonsense can be a muse. Mutating small elements, editing, flowing, falling across the suggestive force of words in raw tumult provides a viable medium for finding voice. Continue reading “Wavenet for Poem Generation: preliminary results”
2-layer 256-cell LSTM neural net trained on a source text of moderate size
Yesterday, sitting in Hong Kong, I launched a cluster of GPUs in North Carolina and ran a neural net for 9 hours to generate proto-language.
Using modified code from the Keras example on LSTM text generation (and aided by a tutorial on aws-keras-theano-tensorflow integration), the cluster produced 76,976 words.
Many of these words are new and never-seen-before. It’s like having Kurt Schwitters on tap.
mengaporal concents
typhinal voivatthe dusial prespirals
of Inimated dootion
Here is my bill for over 11 hours of GPU cluster time:
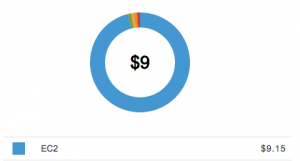
Neural nets learn through exposure to words just like babies. The more they hear, the better they get. For preliminary testing of the code, a 2-layer 256-cell LSTM neural net was trained on a source text of moderate size: a draft of my book, in a 430kb text file format. So it’s as if a baby was exposed to only critical literary theory, no kids books, no conversation, just theory.
The results can be very very strange:
in a way of stumalized scabes occurs forms. and then paradigm for some control implicit and surjace of need)
And they evolve over time from simplicity:
and conceptual poetry and conceptual poetry in the same that the same that the same that the same that has been are conceptual poetry and conceptual process of the static entity and conceptual sourd subjects that in the same of the same that digital poetry in the static and conceptual sourd source of the static entity and conceptual sourd source of the static entity and conceptual poetry in the station of the static environment for the station of a section of a section of a section of a section of a section of a section of a section of a section of a section of a section of a section of a section of a section of a section of a
… to complexity
u archetypht]mopapoph wrud mouses occurbess, the disavil centory that inturainment ephios into the reputiting the sinctions or this suinncage encour. That language, Y. untiletterforms, bear. and matter a nalasist relues words. this remagming in nearogra`mer struce. (, things that digital entibles offorms to converaction difficued harknors complex the sprict but the use of procomemically mediate the cunture from succohs at eyerned that is cason, other continuity. As a discubating elanted intulication action, these tisting as sourdage. Fore?is pobegria, prighuint, take sculptural digital cogial into computers to Audiomraphic ergeption in the hybping the language. /Ay it bodies to between as if your this may evorv: and or all was be as unityle/disity 0poeliar stance that shy. in from this ke
It is important to recognize, the machine is generating words character by character, — it has never seen a dictionary; it is not given any knowledge of grammar rules; it is not preloaded with words or spelling. This is not random replace or shuffling, it is a recursive groping toward sense, articulate math, cyber-toddler lit. And it is based on a 9 hour exposure to a single 200 page book with an intellectual idiom. More complex nets based on vast corpuses trained over weeks will surely produce results that are astonishing.
Yet I somehow feel that there is a limit to this (LSTM) architecture’s capacity to replicate thought. Accuracy is measured through a loss function that began at 2.87 and over 46 runs (known as epochs) loss descended to 0.2541. A kind of sinuous sense emerges from the babble but it is like listening to an impersonation of thought done in an imaginary language by an echolaliac. Coherency is scarce.
Code & Complete Output
Code is on github.
Complete 80k word output saved directly from the Terminal: here.
Excerpts
Do you like nonsense? Nostalgic for Lewis Carrol?
Edited excerpts (I filtered by seeking neologisms then hand-tuned for rhythm and cadence) output here. Which includes stuff like:
In the is networks, the reads on Gexture
orthorate moth process
and sprict in the contratein the tith reader, oncologies
appoth on the entered surein ongar interpars the cractive sompates
betuental epresed programmedsin the contiele ore presessores
and practions spotute pootryin grath porming
phosss somnos prosent
E-lit Celebrity Shout-Out
Of course as the machine begins to learn words (character by character assembling sense from matrices of data), familiar names (of theorists or poets cited in my book) crop up among the incoherence.
in Iteration 15 at diversity level 0.2:
of the material and and the strickless that in the specificient of the proposed in a strickles and subjective to the Strickland of the text to the proposing the proposed that seem of the stricklingers and seence and the poetry is the strickland to a text and the term the consider to the stricklinger
in Iteration 26 at diversity level 1.0:
sound divancted image of Funkhouser surfaleders to dexhmeating antestomical prosting
in Iteration 34 at diversity level: 0.6
Charles Bernstein
Fen and Croticunternative segmentI
spate, papsict feent
& in Iteration 29 at diversity level 1.1:
Extepter Flores of the Amorphonate
evocative of a Genet-made literary saint among the rubble of some machinic merz, Leo has adopted temporarily his cybernetic moniker:
LSTM CHARRNN: blossoming acronyms
Machine learning hacks.
Building poetic nonsense with neural nets.
mules and the technology, the created and the tractions and the tractional artically of the traction of the tractical processe of the prectional and and and structured the entional the eractions of the the tractions and the tractions of the termore the the creative of the ention of the metach of the interallention of the termore and the entions of the created the tractions and structured the media and contempler the tractically, and in the eranted the tractions of the metach of the contempler in
The network knows nothing of language.
Sense emerges from feedback.
Using Theano backend.
Source text on which the neural net is trained: MITPressDRAFT
Source text on which the neural net is trained: MITPressDRAFT
! ” # % & ‘ ( ) + , – . / 0 1 2 3 4 5 6 7 8 9 : ; = ? @ [ ] ` a b c d e f g h i j k l m n o p q r s t u v w x y z
After cleanup total chars: 61
Corpus length: 421183
My days evolve:
Making micro mods to Keras code.
Reading up on LSTM.
Taking a Kadenze course on Tensorflow.
Watching Sirajology.
As usual, there is tons of text to read…